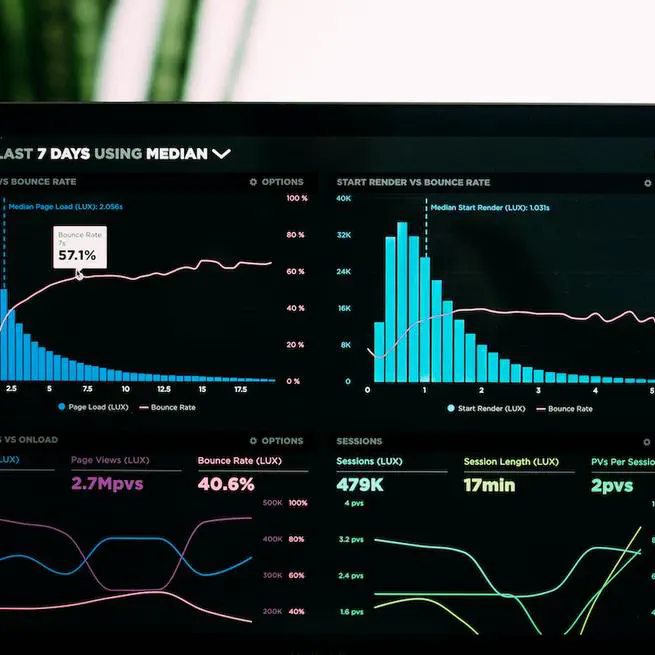
📈 Communicate your results effectively with the best data visualizations
Use popular tools such as Plotly, Mermaid, and data frames.
Oct 25, 2023
👩🏼🏫 Teach academic courses
Embed videos, podcasts, code, LaTeX math, and even test students!
Oct 24, 2023
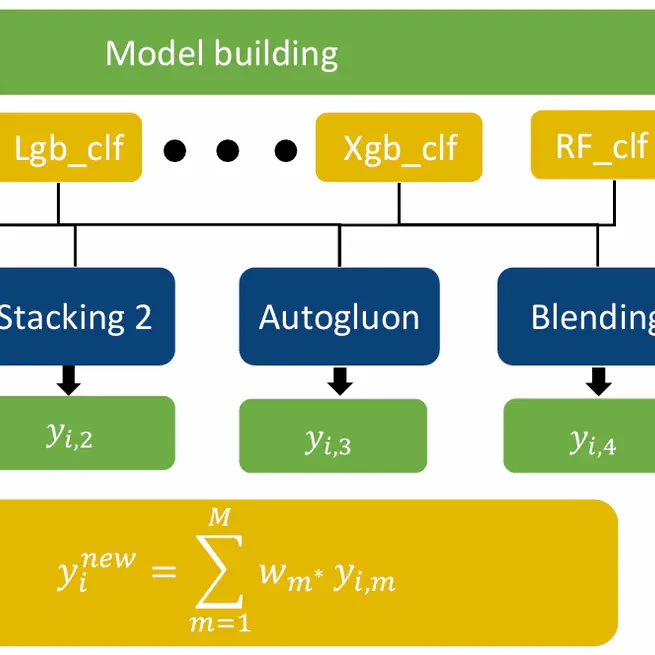
Customer Credit Risk Prediction and Identification
Competition: Third Sichuan University Financial Technology Modeling Competition Award: First Place **Awared by:**The Education Department of Sichuan Provincial This project, presented for the Third Sichuan University Financial Technology Modeling Competition, focuses on customer credit risk prediction and identification. It emphasizes constructing a stable, high-performing binary classification model for credit risk management based on financial data. Key Highlights Data Analysis and Preparation Data Overview: Combined datasets include 24,983 samples and 205 features. After preprocessing, 124 features remain (33 textual and ~33% date-related features). Data Cleaning: Missing values: Median imputation for continuous variables. Mode imputation for discrete variables. Filling with -99 for features with >95% missing. Encoding methods: Count encoding for categories with <10 values. WOE binning for categories with >10 values. Time features are extracted based on hours/minutes or intervals from the current day. Feature Selection and Engineering: Importance-ranked features selected via XGBoost. Featuretools used to generate new feature combinations. Model Building Architecture: Three-layered stacking framework: Layer 1: Base models include CatBoost, LightGBM, XGBoost, and Random Forest. Layer 2: Outputs from base models serve as inputs for four distinct sub-models. Layer 3: Final predictions are generated through normalized weighted voting. Model Optimization: 5-fold cross-validation and grid search are applied to optimize hyperparameters for base models. Evaluation Model performance is assessed using AUC (Area Under the Curve): Individual Models: CatBoost: 0.8486 LightGBM: 0.8476 XGBoost: 0.8464 Random Forest: 0.8423 Stacking and Voting: Stacking 1: 0.8523 Stacking 2: 0.8530 Voting: 0.8594 (Best Performance) Credit Rating System Structure: Customers are classified into 9 levels based on predicted risk, with clear distribution and distinguishable credit tiers. 9.77% of users belong to the top levels (8 and above), reflecting the model’s discriminatory power. Implementation: Integrated with a web-based system using Docker and Vue.js for front-end services. Compared to FICO models, the system provides zones for: Quality customers. Value exploration. Overestimation. Risk elimination. Conclusions and Suggestions The project demonstrates strong modeling capabilities through effective stacking and feature engineering. The authors suggest refining the model for real-world applications and exploring the scalability of the approach for diverse datasets. This project presents a robust credit risk modeling framework with promising performance, practical implications, and room for further enhancement in financial technology applications.
Jan 1, 2023